Documentation Index
Fetch the complete documentation index at: https://private-04b27de1.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.


Li Jiang
Senior Software Engineer at Microsoft

- We introduce RetrieveUserProxyAgent, RAG agents of AutoGen that allows retrieval-augmented generation, and its basic usage.
- We showcase customizations of RAG agents, such as customizing the embedding function, the text split function and vector database.
- We also showcase two advanced usage of RAG agents, integrating with group chat and building a Chat application with Gradio.
Introduction
Retrieval augmentation has emerged as a practical and effective approach for mitigating the intrinsic limitations of LLMs by incorporating external documents. In this blog post, we introduce RAG agents of AutoGen that allows retrieval-augmented generation. The system consists of two agents: a Retrieval-augmented User Proxy agent, calledRetrieveUserProxyAgent, and an Assistant
agent, called RetrieveAssistantAgent; RetrieveUserProxyAgent is extended from built-in agents from AutoGen,
while RetrieveAssistantAgent can be any conversable agent with LLM configured.
The overall architecture of the RAG agents is shown in the figure above.
To use Retrieval-augmented Chat, one needs to initialize two agents including Retrieval-augmented
User Proxy and Retrieval-augmented Assistant. Initializing the Retrieval-Augmented User Proxy
necessitates specifying a path to the document collection. Subsequently, the Retrieval-Augmented
User Proxy can download the documents, segment them into chunks of a specific size, compute
embeddings, and store them in a vector database. Once a chat is initiated, the agents collaboratively
engage in code generation or question-answering adhering to the procedures outlined below:
- The Retrieval-Augmented User Proxy retrieves document chunks based on the embedding similarity, and sends them along with the question to the Retrieval-Augmented Assistant.
- The Retrieval-Augmented Assistant employs an LLM to generate code or text as answers based on the question and context provided. If the LLM is unable to produce a satisfactory response, it is instructed to reply with “Update Context” to the Retrieval-Augmented User Proxy.
- If a response includes code blocks, the Retrieval-Augmented User Proxy executes the code and sends the output as feedback. If there are no code blocks or instructions to update the context, it terminates the conversation. Otherwise, it updates the context and forwards the question along with the new context to the Retrieval-Augmented Assistant. Note that if human input solicitation is enabled, individuals can proactively send any feedback, including Update Context”, to the Retrieval-Augmented Assistant.
- If the Retrieval-Augmented Assistant receives “Update Context”, it requests the next most similar chunks of documents as new context from the Retrieval-Augmented User Proxy. Otherwise, it generates new code or text based on the feedback and chat history. If the LLM fails to generate an answer, it replies with “Update Context” again. This process can be repeated several times. The conversation terminates if no more documents are available for the context.
Basic Usage of RAG Agents
- Install dependencies
- Install
unstructuredin ubuntu
autogen.retrieve_utils.TEXT_FORMATS.
- Import Agents
- Create an ‘AssistantAgent’ instance named “assistant” and an ‘RetrieveUserProxyAgent’ instance named “ragproxyagent”
- Initialize Chat and ask a question
- Create a UserProxyAgent and ask the same question
UserProxyAgent is not related to our autogen since the latest info of
autogen is not in ChatGPT’s training data. The output of RetrieveUserProxyAgent is correct as it can
perform retrieval-augmented generation based on the given documentation file.
Customizing RAG Agents
RetrieveUserProxyAgent is customizable with retrieve_config. There are several parameters to configure
based on different use cases. In this section, we’ll show how to customize embedding function, text split
function and vector database.
Customizing Embedding Function
By default, Sentence Transformers and its pretrained models will be used to compute embeddings. It’s possible that you want to use OpenAI, Cohere, HuggingFace or other embedding functions.- OpenAI
- HuggingFace
Customizing Text Split Function
Before we can store the documents into a vector database, we need to split the texts into chunks. Although we have implemented a flexible text splitter in autogen, you may still want to use different text splitters. There are also some existing text split tools which are good to reuse. For example, you can use all the text splitters in langchain.Customizing Vector Database
We are using chromadb as the default vector database, you can also use mongodb, pgvectordb, qdrantdb and couchbase by simply setvector_db to mongodb, pgvector, qdrant and couchbase in retrieve_config, respectively.
To plugin any other dbs, you can also extend class agentchat.contrib.vectordb.base,
check out the code here.
Advanced Usage of RAG Agents
Integrate with other agents in a group chat
To useRetrieveUserProxyAgent in a group chat is almost the same as you use it in a two agents chat. The only thing is that
you need to initialize the chat with RetrieveUserProxyAgent. The RetrieveAssistantAgent is not necessary in a group chat.
However, you may want to initialize the chat with another agent in some cases. To leverage the best of RetrieveUserProxyAgent,
you’ll need to call it from a function.
Build a Chat application with Gradio
Now, let’s wrap it up and make a Chat application with AutoGen and Gradio.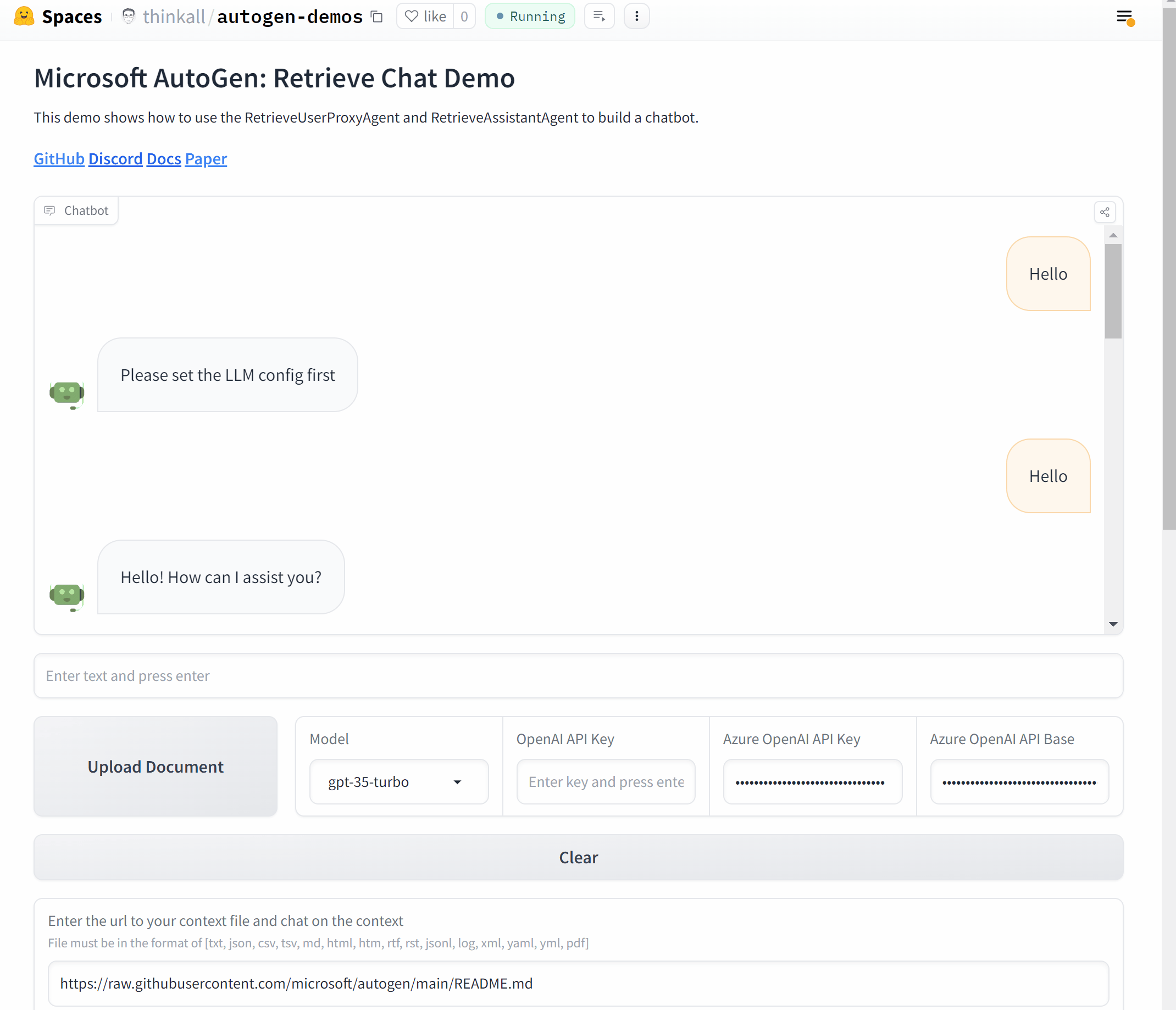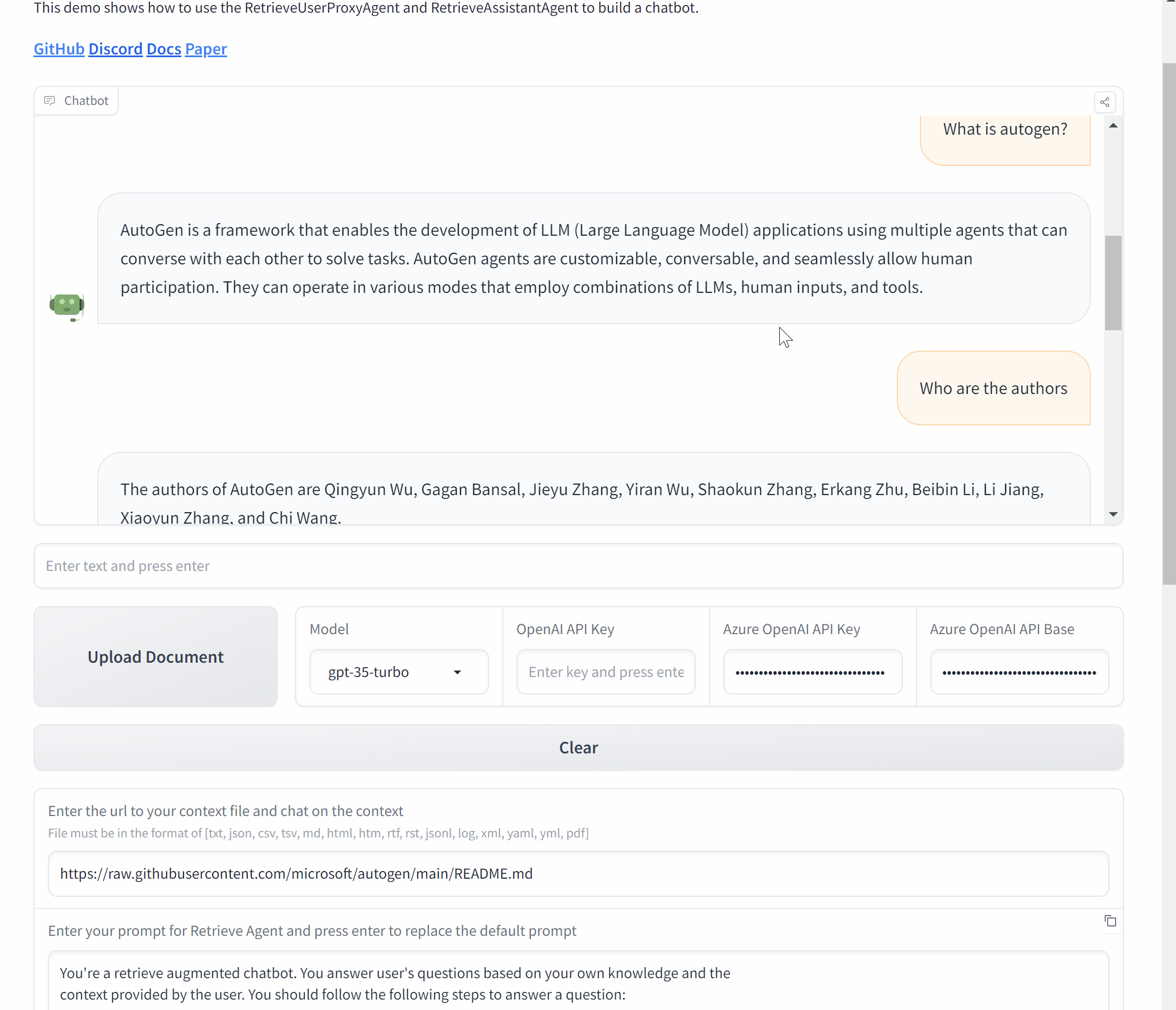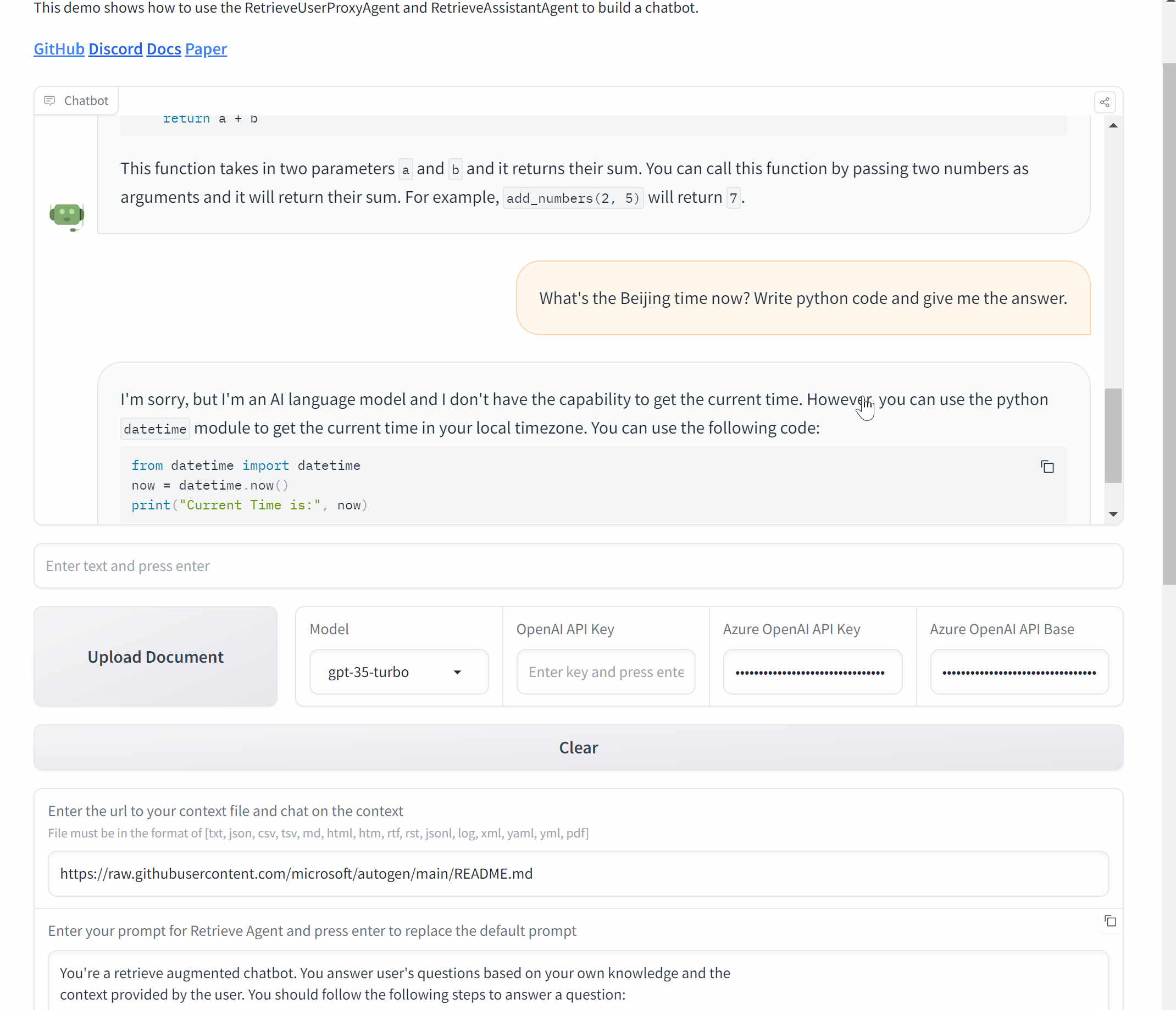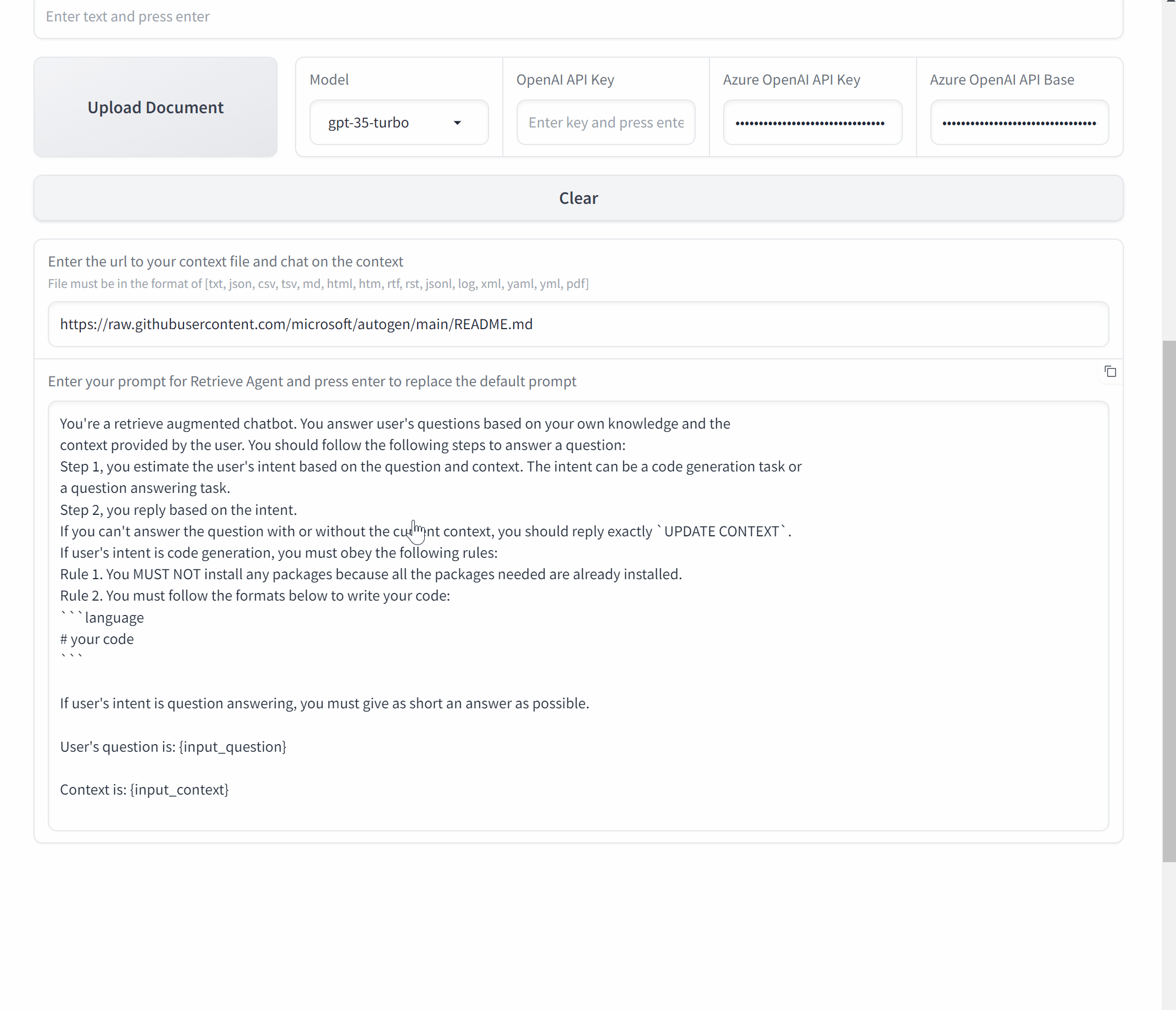
Read More
You can check out more example notebooks for RAG use cases:- Automated Code Generation and Question Answering with Retrieval Augmented Agents
- Group Chat with Retrieval Augmented Generation (with 5 group member agents and 1 manager agent)
- Using RetrieveChat with Qdrant for Retrieve Augmented Code Generation and Question Answering
- Using RetrieveChat Powered by PGVector for Retrieve Augmented Code Generation and Question Answering
- Using RetrieveChat Powered by MongoDB Atlas for Retrieve Augmented Code Generation and Question Answering
- Using RetrieveChat Powered by Couchbase for Retrieve Augmented Code Generation and Question Answering